Scholarly Publishing in a Connected World
Tzviya Siegman, Wiley
WWW2016 - Montreal
Research is sharing knowledge
- Historically, publishing research meant publishing a flat, finished product
- Articles have been read by our peers before and after publication
- The published article is rather immutable
Even retractions and errata are discrete entitities
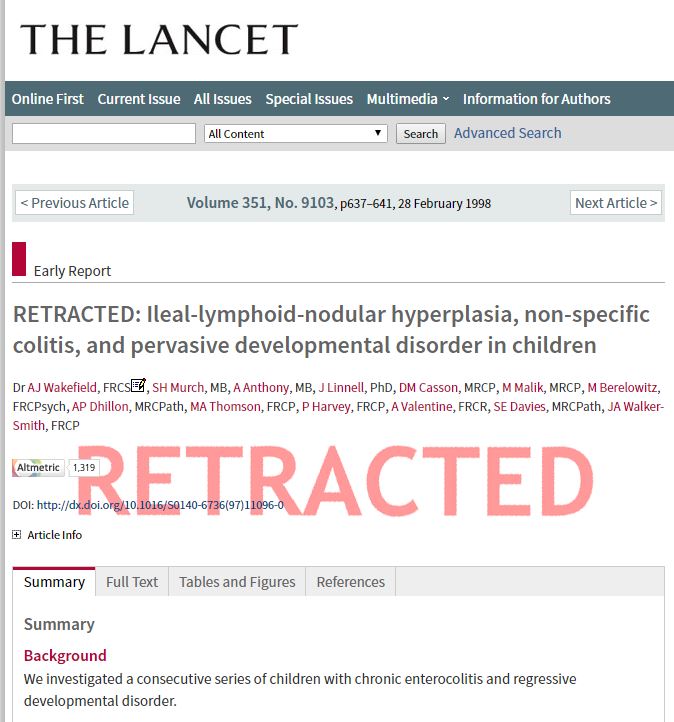
Machines are readers too
- We are beginning to recognize the value of machines reading our research as well
- Using tools of the open web platform can help researchers and even speed up research during times of crisis
Publishing may be a little behind

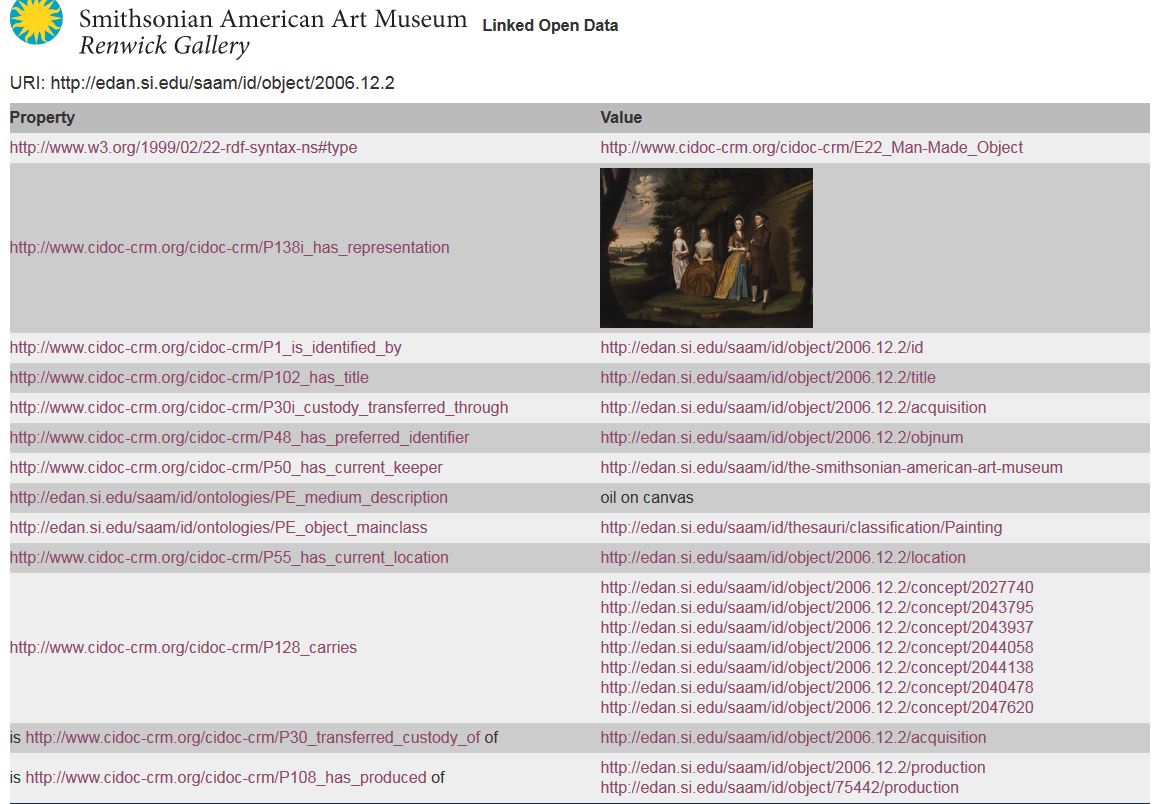
Smithsonian Linked Open Data
http://edan.si.edu/saam/id/object/2006.12.2
History Lesson
- Digitization of scholarly publishing is about the same age as the Web
- In 1995, libraries didn't want to build additional wings to house stacks of journals
- JSTOR was created to solve a real estate problem
- Earliest online journals were HTML
- The appeal and efficiency of desktop publishing was too good to pass up
Pages
- Right now, we have a lot of faith in the “page”
- Citations are usually page-based
- Even when given the choice of HTML, many researchers choose PDF
Benefit from the crossroads
- Reap the benefits of pages, or CSS "fragmentainers"
- Don't be contained by the frozen page of desktop publishing
- Publications can be living documents, with typography, supported by the full stack of web technology
Connected Publishing
Serious electronic literature (for scholarship, detailed controversy and detailed collaboration) must support bidirectional and profuse links, which cannot be embedded; and must offer facilities for easily tracking re-use on a principled basis among versions and quotations.Theodor H. Nelson, "Xanalogical Structure, Needed Now More than Ever: Parallel Documents, Deep Links to Content, Deep Versioning and Deep Re-Use"
Hyper* Research
- Hypertext gives us a lot of the same information as print and a protocol for sharing it
- Hypermedia gives us an interactive layer
- Hyperdata gives us networked, living information
How Are We Doing?
- We are still looking for the best way to convey "deeply intertwingled" information
- Traditional links rot. Is there a better way to convey relationships?
- Can information from one resource change or affect something in another resource?
- Is it possible to add information to a resource without touching it?
Hyper* check
- Hierachical information is pretty comfortable
- Associative information has come a long way
- Convey metadata and relational information without tweaking the content
- Convey data in a manner that does not require hopping in and out of systems
An Associative Index?
Read more about the extensible TEI and XML code base.
Meaningful Metadata
Not too long ago (and often still) author information and titles were just meaningless blobs of text
Linked Data to the rescue!
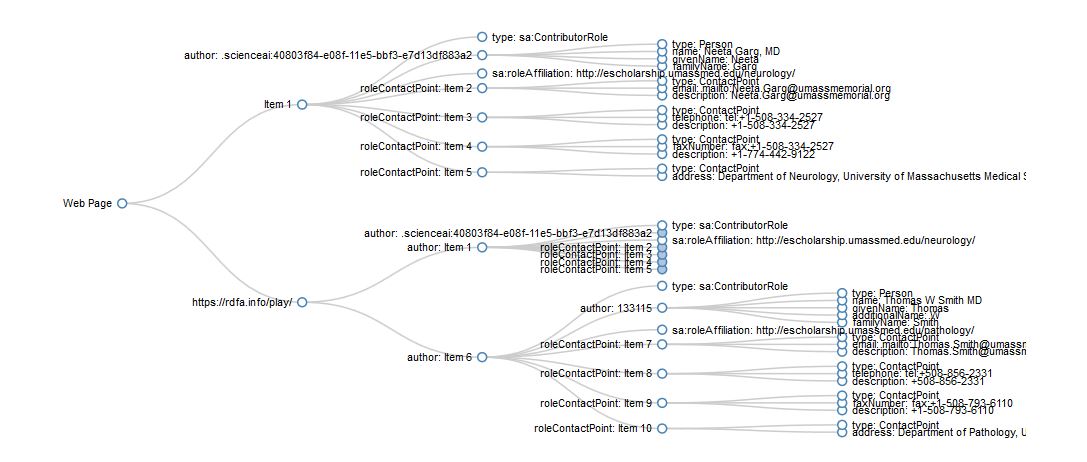
Networked Publications
Our articles are talking to each other
<li property="schema:author">
<span typeof="schema:Person" resource="https://en.wikipedia.org/wiki/Ada_Lovelace">
<meta property="schema:givenName" content="Ada">
<meta property="schema:additionalName" content="Augusta">
<meta property="schema:familyName" content="Lovelace">
<span property="schema:name">Augusta Ada Lovelace</span>
...
Theory vs. Practicality
- RDFa and friends give us the tools to link anything
- A quick look through LOV will show hundreds of open vocabularies, with varying degrees of use
- If I don't find what I need, I can write a new vocabulary or create a namespace and some SKOS equivalents
What is the point?
- Do these endless, unique vocabularies actually assist in linking content?
- Would it help to standardize on a small subset of vocabularies?
Use Case: Curation of Content
- Linked data enables gathering of content by topic
- Wiley Online Library now features hubs
- Users can subcribe to a topic instead of a specific journal
- See American Association for the Study of Liver Disease hub

Publishing Data
- In the past, published data was, by definition, historical
- Tools like IPython, Jupyter, and GitHub allow researchers to publish and never stop!
- Web Annotations, GitHub Pull Requests allow anyone to comment
- Living publications allow for living data
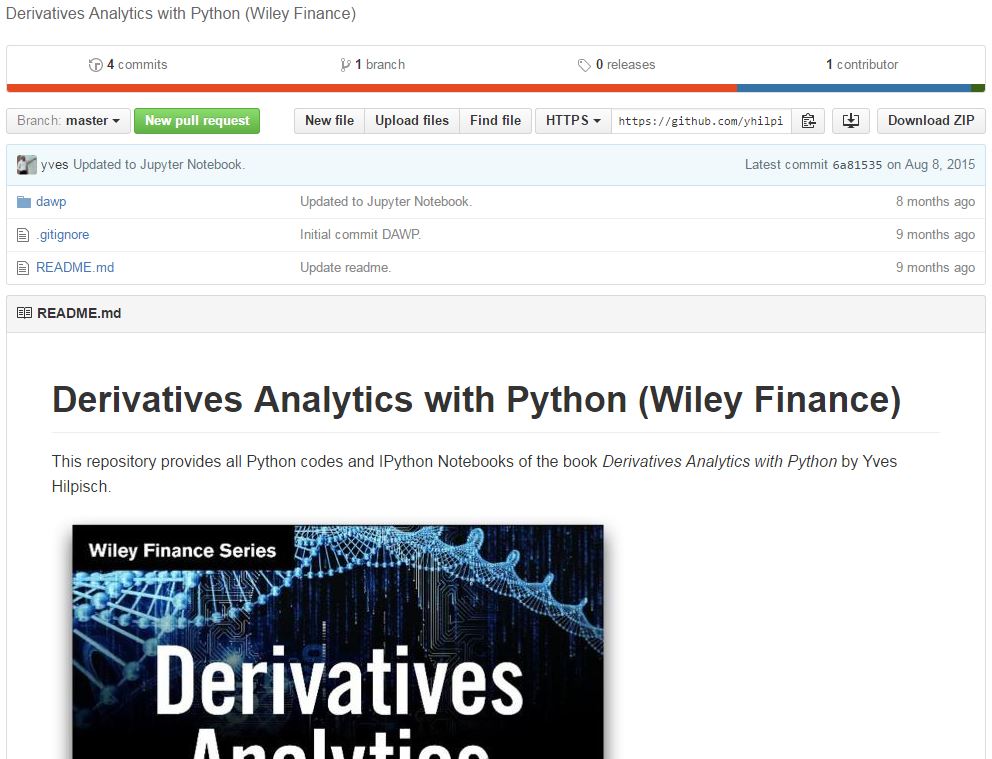
Use Case: Derivatives Analytics with Python (Wiley Finance)
Wiley Finance is a series of books aimed at finance and investment professionals. Often authors make tools such as spreadsheets available to the readers.
- Derivatives Analytics with Python breaks the historical mold of firewalling everything behind a book's results, tables, and figures
- Puts all Python code in an open Github Repository
- The author provides a Jupyter Notebook to host the code on the Quant Platform for a standardized execution environment
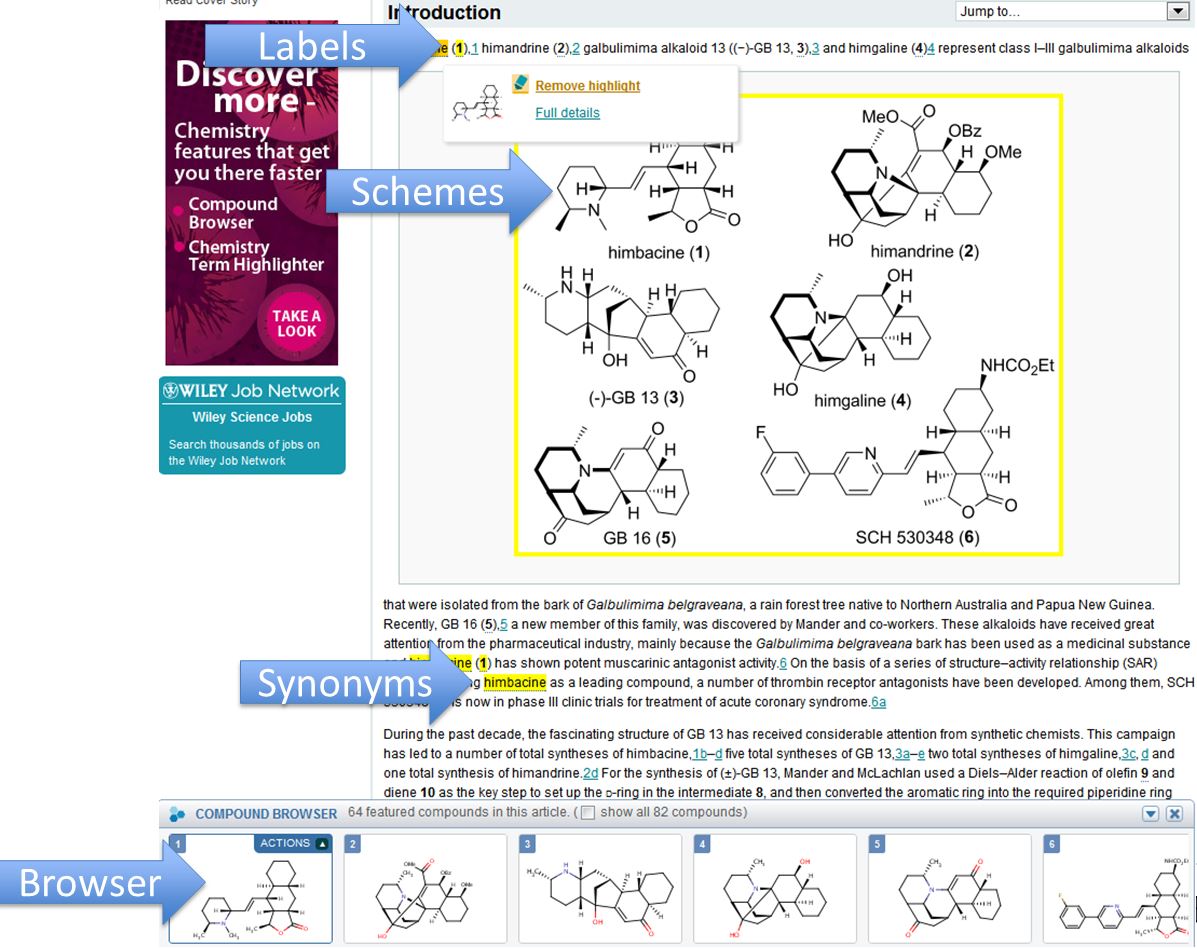
Lessons from the Past
- In 2012 Wiley launched a site called Functional Chemistry
- Instead of publishing raster images of compounds that originated in ChemDraw, we extracted InChIKeys from the ChemDraw files
- This enabled our machines to identifying existing and novel compounds
- Users able to view the compound labels, images, and schemes as well as the spectra associated with compounds

Data Lives
- Live data, annotations allow authors and users to constantly update a publication
- If an author updates the data in GitHub, the graphic representation of it will change in the article
- What, then is the "publication of record"?
- Can this be managed by versioning?
Use Case: Cochrane Library Systematic Reviews
Cochrane Reviews are systematic reviews of primary research in human health care and health policy, and are internationally recognised as the highest standard in evidence-based health care. They may either investigate the effects of interventions for prevention, treatment, and rehabilitation, or alternatively may assess the accuracy of a diagnostic test for a given condition in a specific patient group and setting. A unique feature of Cochrane Reviews is that they are living documents in that they are updated with new evidence that emerges. They were conceived as electronic publications from the outset, and designed to take advantage of features unique to electronic publishing.
There is still work to do
- We have come a long way in exploiting the value of data on the web and data about the web
- Many questions remain
- Interoperability is still a goal!
Thank you
Tzviya Siegman
Wiley
@TzviyaSiegman
tsiegman@wiley.com